What is an index in sql server?
Index
is a way to organize data in a table to make some operations like
searching, sorting, grouping etc faster. So, in other word we need
indexing when sql query has:
1. WHERE clause (That is searching)
2. ORDER BY clause (That is sorting)
3. GROUP BY clause (This is grouping) etc.
Table scan:
Let us assume we have a student table with following schema:
CREATE TABLE Student(
RollNo INT NOT NULL,
Name VARCHAR(50) NULL,
Country VARCHAR(50) NULL,
Age INT NULL
)
And its data as follow:
RollNo
|
Name
|
Country
|
Age
|
101
|
Greg
|
UK
|
23
|
102
|
Sachin
|
India
|
21
|
103
|
Akaram
|
Pakistan
|
22
|
107
|
Miyabi
|
China
|
18
|
108
|
Marry
|
Russia
|
27
|
109
|
Scott
|
USA
|
31
|
110
|
Benazir
|
Banglades
|
17
|
111
|
Miyabi
|
Japan
|
24
|
112
|
Rahul
|
India
|
27
|
113
|
Nicolus
|
France
|
19
|
Right now student table has not any index.
SELECT * FROM Student WHERE RollNo = 111
If we execute above sql query, it will go for table scan i.e. it will scan the RollNo column from beginning to end until it doesn't get the record where RollNo = 111. In this way from RollNo
101 to 111, it has to scan 8 times. If the table has too many rows, say
100K, then the number of scan will increase drastically.
Time complexity of table scan is : O(n)
If we observe estimated execution plan it will look something like:

As we observed, table scan is the least efficient way of scanning the record and hence sql server has introduced index to optimize the scanning process i.e. to decrease the number of scan and hence making the operations faster. In sql server there are two type of index:
1. Clustered index
2. Non-Clustered indexWhat is clustered index in sql server?
When
we create a clustered index on any table, physical organization of data
in the table is changed. Data in the table are stored as
binary search tree(B tree). For example if we will create the clustered
index named CL_Student_Roll with RollNo column of Student table as
key column of clustered index, physical organization of data in the
table will look something like this :

Description of above image:
It
is B Tree representation where top node is called root node and bottom
nodes are called leaf nodes. All the nodes in between are called
intermediate nodes. B Tree can have many intermediate nodes if table has
too many records. In this example there are no intermediate nodes and
we have assumed size of each node is five i.e. each node can keep
maximum five roll numbers. In clustered index leaf nodes keep the memory
address of actual (physical) data row.
Now if we will execute following sql query:
SELECT * FROM Student WHERE RollNo = 111
Since
Student table has clustered index so now it will go for index scan
instead of table scan to search the RollNo = 111. Scan will start from
root node in the clustered index CL_Student_Roll .
Scanning steps:
Scan 1: 107 < 111 so it will go to next element of root node.
Scan
2: 110 < 111 so it will go to the next element of root node. Since
there is not any other element in root node so it will follow right most
link or path.
Scan 3: In leaf node, 110 < 111 o it will go to next element of leaf node.
Scan 4: In leaf node, 111 = 111 so it will follow this path and get the actual data.
Using clustered index we can access the actual data only in 4 scanning while using table scan we had to follow 8 scanning. If table has too many rows then numbers of scan will decrease drastically as compared to table scan.
Time complexity of index scan is: O(log n)
If we observe estimated execution plan, it will look like:

Now table scan has changed to index seek. So it will scan using clustered index CL_Student_Roll
Simple syntax for creating clustered index:
CREATE UNIQUE [CLUSTERED] INDEX <IndexName>
ON <ObjectName>(
<ColumnName> [ASC | DESC ] [ ,...n ]
)
Explanation of each term:
UNIQUE: It is optional. We can specify UNIQUE only when there is no duplicate data in key columns.
<IndexName>: It can be any valid name of the index.
<ObjectName>: It is the name of object on which we are creating index. It can be either table name of view name.
<ColumnName>: It is name of key column. We can specify more than one key columns which is called composite key.
[ASC | DESC]: To specify the order of key column in ascending or descending order.
Some important points about clustered index:
1.
If we create table with primary key, sql server automatically creates
clustered index on that table. No need to create clustered index
manually.
2.
A table can have only one clustered index since physical organization
of data in a table is same as clustered index and any table can have
only one physical organization of data.
3. If clustered index has more than one partition then each partition has a B-tree.
Creating a simple clustered index on student table:
CREATE UNIQUE CLUSTERED INDEX CL_Student_Roll
ON Student(RollNo)
Terms related to estimated execution plan:
Table scan: It is very slow and is used only if table has no clustered index.
Index scan: It is also slow. It is used when table has clustered index and either when non-key columns are present in WHERE clause or when query has not been covered (will discuss later) or both.
Index Seek: It is very fast. Our goal is to achieve this.
If we will keep mouse on any icon in execution plan (GUI) a detailed screen will appear like this:

Terms related to detail section:
Predicate:
It is condition in WHERE clause which is either non-key column or column which has not been covered.
Object: It is name of the source from where it is getting data. It can be name of table, Clustered index or non-clustered index.
Output list: It is a list of names of the columns which it is getting from object.
Seek Predicate: It is condition in WHERE clause which is either key column or fully covered.
Our goal is to move the conditions to the predicate section to seek predicate.
Consider the sql query:
SELECT RollNo FROM Student WHERE Age = 24
If we observe estimated execution plan it will look like:

Predicate is:
[DbName].[dbo].[Student].[Age] = CONVERT _IMPLICIT ( int, [@1], 0)
Object or source is: Cl_Student_Roll that is clustered index we have created.
So
it is obvious that it is scanning using clustered index and hence it is
index scan. So it is less efficient since searching is being done using
the column age which is non-key column of clustered index
CL_Student_Roll. Its key column is RollNo. Time complexity of index scan
is same as table scan i.e. O (n). As we know table can have only one
clustered index, to make such type of query more efficient sql server
has introduced non-clustered index.
Important points about clustered index:
1. In create table statement we can specify CLUSTERED and NONCLUSTERED keyword on only those columns which have either PRIMARY KEY or UNIQUE constraints. For example:
CREATE TABLE Emp(
ID INT PRIMARY KEY CLUSTERED,
RegNo INT UNIQUE NONCLUSTERED
)
Default value of PRIMARY KEY constraints is CLUSTERED if table has no existing clustered index or if we have not specified CLUSTERED index on any columns of UNIQUE constraint. Default value of UNIQUE constraints is NONCLUSTERED
2.
Creating a primary key on a table also creates a unique non-clustered
index of table if table has any existing clustered index.
3. A table or view can have only one clustered index.
4. Physical order of rows of table is same as logical order of key columns of clustered index.
5. Leaf nodes of clustered index keep actual data rows.
What is non clustered index
in sql server?
It is
logical organization of data in a table. A table can have 1023 non-clustered
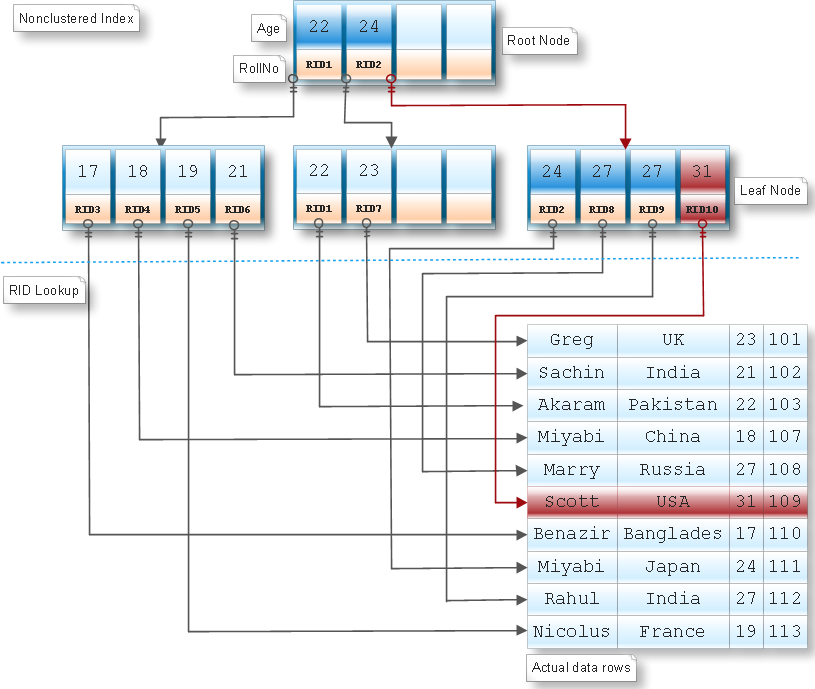
index. A non-clustered index can be of two types as:
1. Heap
2. Based
on clustered index.
If table
has clustered index then leaf node of non-clustered index keeps the key columns
of clustered index. If the table has no clustered index then leaf node of
non-clustered index keeps RID which is unique to each row of table. Such
non-clustered index is called heap.
Non-clustered
index based on clustered index:

Description of above image:
It is the
B-tree representation of non-clustered index NCI_Student_Age where lower
section of dotted line is also B-tree of clustered index CL_Student_Roll. Top
node of non-clustered index is called root node and bottom nodes are called
leaf node. All the nodes in between root node and leaf nodes are called
intermediate nodes. A B-tree can have many intermediate nodes in case table has
too many records. In this example there is no intermediate node and we have
assumed size of each node is four i.e. each node can keep maximum five Age.
Important
points about non-clustered index based on clustered index:
1. All
the nodes keep key columns of non-clustered index and key column of unique
clustered index.
2. If
clustered index is not unique then instead of key column of clustered index it
keeps a unique row identifier of the actual data rows of table.
3. Apart
from points above, a leaf node also keeps the included columns of non-clustered
index. (We will discuss about included column later)
Now if we
will execute following sql query:
SELECT * FROM Student WHERE RollNo = 111
Since
Student table has clustered index, now it will go for index scan instead of
table scan to search the RollNo = 111. Scan will start from root node
in the clustered index CL_Student_Roll.
SELECT Country
FROM Student WITH
(INDEX (NCI_Student_Age))
WHERE Age = 31
Note:
Here we have added WITH clause only because sql server uses the
non-clustered index NCI_Student_Age, otherwise it will not
use non-clustered index or will use if table has too many records. We
will discuss why is it so later.
Execution
plan of above query will look like this:

Meaning
of above execution plan:
Sql server
will first use non-clustered index NCI_Student_Age and find
out the corresponding value of key column i.e. RollNumber of
clustered index (It is called key look up) using nested loop and find out
the value of column Country.
Scanning steps:

Scan 1:
22 < 31 so it will go to next element of root node.
Scan 2:
24 < 31 so it will go to the next element of root node. Since there is
not any other element in root node so, it will follow right most link or path.
Scan 3:
In leaf node, 24 < 31 o it will go to next element of leaf node.
Scan 4:
In leaf node, 24 < 31 o it will go to next element of leaf node.
Scan 5:
In leaf node, 27 < 31 o it will go to next element of leaf node.
Scan 6:
In leaf node, 27 < 31 o it will go to next element of leaf node.
Scan 7:
In leaf node, 31 = 31. It will get value key column of
non clustered index i.e. RollNo which it equal to 109.
Scan 9:
From here it will use clustered index CL_Student_Roll to get the values of
column Country name of RollNo = 31. In root node of
clustered index 107 < 109 so, it will go to next element of root node.
Scan 10:
110 > 109 so it will go through this link.
Scan 11:
In leaf node, 108 < 109 so, it will go to next element of leaf node.
Scan 12:
In leaf node, 107 < 109 so, it will go to next element of leaf node.
Scan 13:
In leaf node, 109 = 109 so it will follow this path and get the actual data
that is value of column Country which is USA.
Simple syntax of
creating a non-clustered index
CREATE [UNIQUE] NONCLUSTERED INDEX <IndexName>
ON <Table_or_view_name>(<ColumnName_Key>[ASC|DESC] [ ,...n ])
[INCLUDE (<ColumnName_Include> [,...n])]
<IndexName>:
It is any valid name of index.
<Table_or_view_name>: It
is name of the table or view on which we want to create the
non-clustered index.
<ColumnName_Key>:
It is name of the key columns
for clustered index separated by comma. Values of these
columns are present in each node of a clustered index. It has following
restrictions:
1. We can
specify maximum 16 column names.
2. Sum of
size of the columns cannot be more than 900 bytes.
3. All
columns must belong to same table.
4. Data
type of columns cannot
be ntext, text, varchar (max), nvarchar (max), varbinary (max), xml,
or image
5. It
cannot be non-deterministic computed column.
<ColumnName_Include>:
Due to above restrictions on <ColumnName_Key> columns, we can include
more columns of table or view in the INCLUDE section. Date of include columns
are only present in the leaf node of clustered index. It has
also some restrictions:
1. Data
type of columns cannot be text, ntext, and image.
2.
A column cannot be present in key columns as well as can not
include column at the same time. Also repetition of columns are not
allowed.
Good practice:
If possible we should try to add all columns of WHERE clause in key
columns list and all columns of SELECT clause in the INCLUDE columns of a
non-clustered index.
Covering
of queries:
If we include all
the the columns of a SELECT statement either as key columns or
INCLUDE columns in non-clustered index such queries are called
covered query. For example consider on query:
SELECT Name,Country
FROM Student
WHERE RollNo = 108 AND Age = 27
Non-clustered index
1:
CREATE NONCLUSTERED INDEX NCI_1
ON Student (RollNo,Age)
This
index doesn't cover the above SELECT statement.
Non-clustered index
2:
CREATE NONCLUSTERED INDEX NCI_2
ON Student (RollNo,Age,Name)
This
index doesn't cover the above SELECT statement.
Non-clustered index
3:
CREATE NONCLUSTERED INDEX NCI_3
ON Student (RollNo,Age,Name,Country)
This
index covers the above SELECT statement.
Non-clustered index
4:
CREATE NONCLUSTERED INDEX NCI_4
ON Student (RollNo,Age)
INCLUDE
(Name,Country)
This
index covers the above SELECT statement.
Now consider on last index we have created that is
CREATE NONCLUSTERED INDEX NCI_Student_Age
ON Student (Age)
This
index doesn't cover the sql query:
SELECT Country
FROM Student
WHERE Age = 31
Due to
which sql server doesn't use the index NCI_Student_Age.
Execution plan of this query will look like:

Sql server
follows Index scan which is same as table scan and it is a slow process.
If we
will use forcefully non-clustered index NCI_Student_Age as
SELECT Country
FROM Student WITH
(INDEX (NCI_Student_Age))
WHERE Age = 31
Its execution plan will look
like:

Here
problem is it is partiality index seek process that is, to get value
of column Country it has to go through (key look up) the clustered index
CL_Student_Roll since non-clustered index doesn't keep the value
of column Country. We can optimize this query by creating a new index
which covers the SELECT statement.
CREATE NONCLUSTERED INDEX NCI_Student_Country
ON Student (Age)
INCLUDE
(Country)
After
creating this index, execution plan will look like:

Now there
is no key look up and it is fully index seek. Structures of
index NCI_Student_Country will look like this:

We can
observe key columns of clustered index keep all the nodes while INCLUDE columns
are only kept by leaf node. To perform this query:
SELECT Country
FROM Student
WHERE Age = 31
Sql server
will not use clustered index since data of
Country columns are present in non-clustered
index NCI_Student_Country. So, there is no need of key look up.
Non-clustered index
based on heap:
A table
without any clustered index is called heap. It is possible to create
a non-clustered index on such tables which do not have
any clustered index. Main difference between
non-clustered index on clustered index and non-clustered index on heap is, it keeps the RID (i.e. Row ID) in the leaf node of non-clustered index instead of key column of
clustered index which is pointer to the actual data rows. Suppose we
have a Student table which do not have any clustered index. Now we want to
create a non-clustered index:
CREATE INDEX NCI_Heap
ON Student (Age)
If we
will check the execution plan of this query:
SELECT Country
FROM Student WITH
(INDEX (NCI_Heap))
WHERE Age = 31
It will look something like this:

From
execution plan, we can observe that it is using RID look up instead of key look up.
Note: RID
of each row of a table is generated by sql server
using file identifier, page number and number of the row on the page
etc.
Organizations
of non-clustered index on heap will look something like this:
We can
remove the RID look up in the execution plan
by covering the query in non-clustered index on heap that is:
CREATE INDEX NCI_Heap_Country
ON Student (Age)
INCLUDE
(Country)
Now
execution plan of query:
SELECT Country FROM Student WHERE Age = 31
Will look like:

No comments:
Post a Comment